Verizon data scientist Jingjing Cannon is passionate about predictive modeling and machine learning, and she has great skill at applying the tech for product and market insight.
Jingjing’s recent work has focused on product launch; a strong product first impression is key to market success, making launch a critical customer journey stage. Voice of the Customer (VOC) text analytics is her go-to method.
Text analytics: The most recent GRIT study, covering market research, lists text analytics as the number 2 emerging method, following only online communities. Emerging? GRIT reports 46% adoption rate – that’s hardly emerging – and 30% “under consideration.” The technology is delivering results for Verizon, as Jingjing describes in an interview I conducted in the run up to the Sentiment Analysis Symposium, March 26-27 in New York, where Jingjing will be speaking.
This interview of Verizon data scientist Jingjing Cannon interview covers…
How Verizon Uses Voice of Customer Data to Guide Product Launches

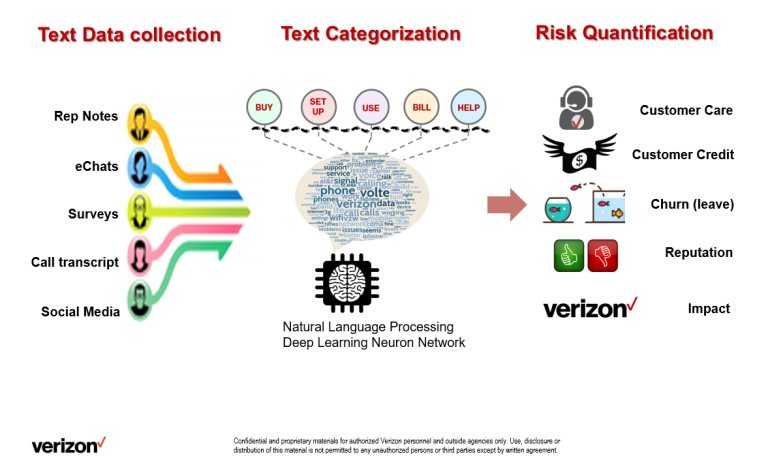
Seth Grimes> You work with voice of the customer data from diverse channels including customer calls, online chat, surveys, and social media. What sort of signals are most relevant?
Jingjing Cannon> I have been working on product launches, and the most useful source is internal data: customer calls, online chat, store visit, etc. Customers interact with a company when they have questions or complaints, so these types are direct sources to uncover customer pain points as well as process problems within a business during product launch.
Surveys and social media are good for a general understanding of how customers feel about the product. However, people do not always take an action (such as buy or not buy, churn or not churn) on what they say, so these channels are good data sources for reputational and sentimental measurements in my opinion.
Seth> Product launches? What’s the angle there?
Jingjing> New product launch is an exciting but risky area for any business. A critical question: “How can we assess performance and risk, related to customer satisfaction, in a timely manner?”
We developed a new-product risk model to identify and quantify customer pain points throughout customer journey at stages including learn, buy, get, use, pay and stay/leave (LB-GUPS). We apply advanced text analytics for true and real time voice of customer. We utilize sentiment analysis, natural language processing, and deep learning to classify large scale of customer feedbacks bucketing them into customer journey stages. A quantitative classification approach uncovers the main revenue-driving pain points and root causes. This risk model predicts how new-product launches impact company revenue and provide early development risk monitoring to guide decision making.
Seth> You also do churn and fraud modeling work. Does your work extend to prescriptive analytics, to Dos and Don’ts for customer engagement?
Jingjing> Yes, prescriptive analytics is an import part of my work. From voice of customer data I collected from different channels, I was able to identify and quantify the top strengths and top opportunities of a new product. After identifying strengths and customer pain points, the quantification analysis to connect each topic to revenue and expense impact is very important because it provides the insights of how each topic is driving the revenue for the company. This risk quantification analysis allows me to prioritize Dos and Don’ts.
Besides Dos and Don’ts, I also provided actionable insights from data on ‘How to Do.’ I applied text analytics to our ticketing data, which includes resolutions when the ticket is closed. Therefore, for each ticket reason, I sorted the solutions by their frequency. By matching the feedback to the closed tickets, the best solution we have for each customer pain point is uncovered and communicated back to our business partners and customer reps. This prescriptive analytics also bring the possibility to implement certain business process based on the best resolutions to eliminate the customer pain point and better assist developing a ‘defect-free’ product.
Seth> Can you quantify the value of this work: Verizon saved $X or made $Y in additional revenue or captured Z additional customers, via VOC programs? Or are these stats closely guarded secrets?
Jingjing> As a data scientist in the Forensics & Analytics Advisory Services Team (FAAST) within the risk management unit, my major accountability is to assess risk from data. Therefore, the financial benefits of our work is more from a cost saving perspective. Take the New Product Launch project as an example. I quantified how much it would cost our company if we don’t do each customer journey step correctly.
Currently, I am working with different business units to implement some solutions to reduce call rate. The call rate for a new product is about 15 times higher than the benchmark from the same sales channel. Our target is a 40% reduction in call rate in the next three months, which will save a significant amount of operational cost monthly.
Seth> Your toolset includes Teradata Aster and Python for text analytics and Tableau for data visualization. What Python packages? What’s attractive about Aster text analytics? And I assume your churn and fraud modeling work also uses Aster?
Jingjing> The main data science technique I used was to solve a text classification problem. There were a few experiments we did for this classification problem. One approach was unsupervised machine learning using TensorFlow to uncover the clusters within the text data. Another approach was supervised machine learning leverage model based classifier, such as SVM and Naïve Bayes. With a very short timeline, we found the most effective and the quickest way was semi-supervised machine learning as building a rule-based keywords dictionary using python library Word2Vec from Gensim.
The attractive feature of Aster text analytics is that it could be a one stop platform from ETL to advanced analytics. It solved one of data scientists’ pain points: transferring data between different coding environments. The other thing I want to mention is that, as data security is always the top priority for Verizon, Teradata aligns with this expectation. The majority of churn and fraud detection modeling work is completed in SAS, SPSS, R and Python.
Seth> In your Sentiment Analysis Symposium presentation, you’ll be talking about a new Verizon product risk model to identify and quantify customer pain points throughout customer journey. How good in industry at journey modeling, rather than just study of isolated touchpoints?
Jingjing> This risk model assesses risks throughout the whole customer journey: learn, buy, setup, use, pay, get help and stay/leave. There was further detailed analysis on the touchpoints in each customer journey step.
Seth> You’re finishing up a PhD on computational neuroscience, looking at how behaviors are controlled. Is there a link to your Verizon work?
Jingjing> Artificial neuron network link my academia research to my data science work at Verizon. For my PhD research, the application of artificial neural network allows the testing of how intrinsic properties of neuronal networks can control certain behaviors without conducting biological experiments on human brains. For the data science work, neuronal network based modeling allows the testing of how predictive variables can control predictive targets, such as probability of churn or similarity of words in the documents.
Seth> My usual closing question: What’s next? What will you be focused on two years hence, and five?
Jingjing> With an academic background, I have the passion to bridge academia and industry in the Data Science field.
One direction is to promote a research atmosphere at my workplace by mentoring people with research attitude and critical thinking mindset. I believe this will enhance a positive work environment to train top data scientists in industry who can self-train continuously to keep up with cutting edge techniques and, also, be an influencer.
The other direction is to bring data science problems from industry back to academia and promote collaborations. I believe a healthy eco-system between academia and industry would push data science forward and have a positive impact on the society.
Seth> Thanks Jingjing. I’m looking forward to your Sentiment Analysis Symposium talk on March 27.