Computational linguists and computer scientists, among them University of Texas professor Jason Baldridge, have been working for over fifty years toward algorithmic understanding of human language. They’re not there yet. They are, however, doing a pretty good job with important tasks such as entity recognition, relation extraction, topic modeling, and summarization. These tasks are accomplished via natural language processing (NLP) technologies, implementing linguistic, statistical, and machine learning methods.

NLP touches our daily lives, in many ways. Voice response and personal assistants — Siri, Google Now, Microsoft Cortana, Amazon Alexa — rely on NLP to interpret requests and formulate appropriate responses. Search and recommendation engines apply NLP, as do applications ranging from pharmaceutical drug discovery to national security counter-terrorism systems.
NLP, part of text and speech analytics solutions, is widely applied for market research, consumer insights, and customer experience management. The more consumer-facing systems know about people — individuals and groups — their profiles, preferences, habits, and needs — the more accurate, personalized, and timely their responses. That form of understanding — pulling clues from social postings, behaviors, and connections — is the business Jason’s company, People Pattern, is in.
I think all this is cool stuff so I asked two favors of Jason. #1 was to participate in a conference I organize, the up-coming Sentiment Analysis Symposium, taking place July 12 in New York. He agreed. #2 was to respond to a series of questions — responses relayed in this article — exploring approaches to —
The Analytics of Language, Behavior, and Personality
Seth Grimes> People Pattern seeks to infer human characteristics via language and behavioral analyses, generating profiles that can be used to predict consumer responses. What are the most telling, the most revealing sorts of thing people say or do that, for business purposes, tells you who they are?
Jason Baldridge> People explicitly declare a portion of their interests in topics like sports, music, and politics in their bios and posts. This is part of their outward presentation of their selves: how they wish to be perceived by others and which content they believe will be of greatest interest to their audience. Other aspects are less immediately obvious, such as interests revealed through the social graph. This includes not just which accounts they follow, but the interests of the people they are most highly connected to (which may have been expressed in their posts and their own graph connections).
A person’s social activity can also reveal many other aspects, including demographics (e.g. gender, age, racial identity, location, and income) and psychographics (e.g. personality and status). Demographics are a core set of attributes used by most marketers. The ability to predict these (rather than using explicit declarations or surveys) enables many standard market research questions to be answered quickly and at a scale previously unattainable.
Seth> And what can one learn from these analyses?
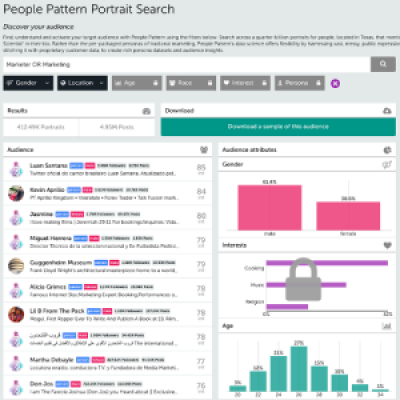
Personas and associated language use.
As a whole, this kind of analysis allows us to standardize large populations (e.g. millions of people) on a common set of demographic variables and interests (possibly derived from people speaking different languages), and then support exploratory data analysis via unsupervised learning algorithms. For example, we use sparse factor analysis to find the correlated interests in an audience and furthermore group the individuals who are best fits for those factors. We call these discovered personas because they reveal clusters of individuals with related interests that distinguish them from other groups in the audience, and they have associated aggregate demographics—the usual things that go into building a persona segment by hand.
We can then show the words, phrases, entities, and accounts that the individuals in each persona discuss with respect to each of the interests. For example, one segment might discuss Christian themes with respect to religion, while others might discuss Muslim or New Age ones. Marketers can then use these to create tailored content for ads that are delivered directly to the individuals in a given persona, using our audience dashboard. There are of course other uses, such as social science questions. I’ve personally used it to look into audiences related to Black Lives Matter and understand how different groups of people talk about politics.
Our audience dashboard is backed by Elastic Search, so you can also use search terms to find segments via self-declared allegiances for such polarizing topics.
A shout-out —
Personality and status are generally revealed through subtle linguistic indicators that my University of Texas Austin colleague James Pennebaker has studied for the past three decades and is now commercializing with his start-up company Receptiviti. These include detecting and counting different types of words, such as function words (e.g. determiners and prepositions) or cognitive terms (such as “because” and “therefore”), and seeing how a given individual’s rates of use of those word classes compares to known profiles of the different personality types.
So personas, language use, topics. How do behavioral analyses contribute to overall understanding?
Many behaviors reveal important aspects about an account that a human would struggle to infer. For example, the times at which an account regularly posts is a strong indicator of whether they are a person, organization or spam account. Organization accounts often automate their sharing, and they tend to post at regular intervals or common times, usually on the hour or half hour. Spam accounts often post at a regular frequency — perhaps every 8 minutes, plus or minus one minute. An actual person posts in accordance with sleep, work, and play activities, with greater variance — including sporadic bursts of activity and long periods of inactivity.
Any other elements?
Graph connections are especially useful for bespoke, super-specific interests and questions. For example, we used graph connections to build a pro-life/pro-choice classifier for one client to rank over 200,000 individuals in greater Texas on a scale from most likely to be pro-life to most-likely to be pro-choice. By using known pro-life and pro-choice accounts, it was straightforward to gather examples of individuals with a strong affiliation to one side or the other and learn a classifier based on their graph connections that was then applied to the graph connections of individuals who follow none of those accounts.
Could you say a bit about how People Pattern identifies salient data and makes sense of it, the algorithms?
The starting point is to identify an audience. Often this is simply the people who follow a brand and/or its competitors, or who comment on their products or use certain hashtags. We can also connect the individuals in a CRM to their corresponding social accounts. This process, which we refer to as stitching, uses identity resolution algorithms that make predictions based on names, locations, email addresses and how well they match corresponding fields in the social profiles. After identifying high confidence matches, we can then append their profile analysis to their CRM data. This can inform an email campaign, or be the start for lead generation, and more.
Making sense of data — let’s look at three aspects — demographics, interests, and location —
Our demographics classifiers are based on supervised training from millions of annotated examples. We use logistic regression for attributes like gender, race, and account type. For age, we use linear regression techniques that allow us characterize the model’s confidence in its predictions — this allows us to provide more accurate aggregate estimates for arbitrary sets of social profiles. This is especially important for alcohol brands that need to ensure they are engaging with age-appropriate audiences. All of these classifiers are backed by rules that detect self-declared information when it is available (e.g. many people state their age in their bio).
We capture explicit interests with text classifiers. We use a proprietary semi-supervised algorithm for building classifiers from small amounts of human supervision and large amounts of unlabeled texts. Importantly, this allows us to support new languages quickly and at lower cost, compared to fully supervised models. We can also use classifiers built this way to generate features for other tasks. For example, we are able to learn classifiers that identify language associated with people of different age groups, and this produces an array of features used by our age classifiers. They are also great inputs for deep learning for NLP and they are different from the usual unsupervised word vectors people commonly use.
For location, we use our internally developed adaptation of spatial label propagation. With this technique, you start with a set of accounts that have explicitly declared their location (in their bio or through geo tags), and then these locations are spread through graph connections to infer locations for accounts that have not stated their location explicitly. This method can resolve over half of individuals to within 10 kilometers of their true location. Determining this information is important for many marketing questions (e.g. how does my audience in Dallas differ from my audience in Seattle?) It obviously also brings up privacy concerns. We use these determinations for aggregate analyses but don’t show them at the individual profile level. However, people should be aware that variations of these algorithms are published and there are open source implementations, so leaving their location field blank is by no means sufficient to ensure your home location isn’t discoverable by others.
My impression is that People Pattern, with an interplay of multiple algorithms and data types and multi-stage analysis processes, is a level more complex than most new-to-the-market systems. How do you excel while avoiding over-engineering that leads to a brittle solution?
It’s on ongoing process, with plenty of bumps and bruises along the way. I’m very fortunate that my co-founder, Ken Cho, has deep experience in enterprise social media applications. Ken co-founded Spredfast [an enterprise social media marketing platform]. He has strong intuitions on what kind of data will be useful to marketers, and we work together to figure out whether it is possible to extract and/or predict the data.
We’ve struck on a number of things that work really well, such as predicting core demographics and interests and doing clustering based on those. Other things have worked well, but didn’t provide enough value or were too confusing to users. For example, we used to support both interest-level keyword analysis (which words does this audience use with respect to “music”) and topic modeling, which produces clusters of semantically related words given all the posts by people in the audience, in (almost) real-time. The topics were interesting because they showed groupings of interests that weren’t captured by our interest hierarchy (such as music events), but it was expensive to support topic model analysis given our RESTful architecture and we chose to deprecate that capability. We have since reworked our infrastructure so that we can support some of those analyses in batch (rather than streaming) mode for deeper audience analyses. This is also important for supporting multiple influence scores computed with respect to a fixed audience rather than generic overall influence scores.
Ultimately, I’ve learned to think about approaching a new kind of analysis not just with respect to the modeling, but as importantly to consider whether we can get the data needed at the time that the user wants the analysis, how costly the infrastructure to support it will be, and how valuable it is likely to be. We’ve done some post-hoc reconsiderations along these lines, which has led to streamlining capabilities.
Other factors?
Another key part of this is having the right engineering team to plan and implement the necessary infrastructure. Steve Blackmon joined us a year ago, and his deep experience in big data and machine learning problems has allowed us to build our people database in a scalable, repeatable manner. This means we now have 200+ million profiles that have demographics, interests and more already pre-computed. More importantly, we now have recipes and infrastructure for developing further classifiers and analyses. This allows us to get them into our product more quickly. Another important recent hire was our product manager Omid Sedaghatian. Omid is doing a fantastic job of figuring out what aspects of our application are excelling, which aren’t delivering expected value, and how we can streamline and simplify everything we do.
Excuse the flattery, but it’s clear your enthusiasm and your willingness to share your knowledge are huge assets for People Pattern. Not coincidentally, your other job is teaching. Regarding teaching — to conclude this interview — I recruited you to speak at the 2016 Sentiment Analysis Symposium in New York, and pre-conference you’ll present a tutorial, Computing Sentiment, Emotion, and Personality. Could you give us the gist of the material you’ll be covering?
Actually, I just did. Well, almost.
I’ll start the tutorial with a natural language processing overview and then cover sentiment analysis basics — rules, annotation, machine learning, and evaluation. Then I’ll get into author modeling, which seeks to understand demographic and psychographic attributes based on what someone says and how they say it. This is in the tutorial description: We’ll look at additional information that might be determined from non-explicit components of linguistic expression, as well as non-textual aspects of the input, such as geography, social networks, and images, things I’ve described in this interview. But with an extended, live session you get depth and interaction, and an opportunity to explore.
Thanks Jason. I’m looking forward to your session.
good article