Topic identification is a top-of-the-list need for organizations working with large volumes of online, social, and enterprise text. Along with entity resolution, concept identification, relation extraction, summarization, and sentiment analysis, topic modeling is a key natural language processing (NLP) function.
Premise number 2: Applied NLP — text analytics — remains as much art as science, requiring a combination of domain and technical expertise.

How better to explore topic modeling and NLP advances than via an interview with a leading practitioner? This article features an interview with Lev Konstantinovskiy, a data scientist who is community manager for gensim, which offers open-source topic modeling for Python programmers.
We’ll start with an introduction —
Topic Modeling 101
Some topics are abstract and some are concrete. Examples: the economy versus Donald J. Trump. A topic may cover facts or it may be subjective: 2015 Amazon best-sellers versus themes of books I like. Ability to apply a topic model — to sort, filter, analyze, and recommend, based on topic understanding — at Web, device, social, and Internet of Things (IoT) scale — will help you navigate the digital world.
Library catalogs rely on topic models, as do eBay, Amazon, Rakuten, and Taobao. The shopping sites’ categories were designed top-down by expert analysts although digital sites do readjust to factor in statistical study of usage patterns. Stats also enable bottom-up topic modeling that responds to actual content, whether the source is social postings, presidential-debate transcripts, online news, or e-mail subject to e-discovery legal rules.
Stats-reliant, data-rooted topic modeling may seem abstruse, the concept that “documents are mixtures of topics, where a topic is a probability distribution over words,” per cognitive scientists Mark Steyvers and Tom Griffiths. But really the notion is simple, that a document’s topics are identified according to relative frequency of words used. Key properties, for instance that “models can connect words with similar meanings and distinguish between uses of words with multiple meanings” (quoting the authors of the MALLET language machine learning package), translate into ability to make important, situational distinctions.
A few lines about gensim and NLP, and then on to the interview.
Premise number 3: Python is a great platform for text analysis. I’m a big fan — I wrote my first Python program back in 1996 — and I’ve watched Python NLP’s advance with great interest. NLTK, the Natural Language Toolkit, has long been the default choice for work with human language data. Launched more recently, gensim topic modeling, originally devised by Radim Řehůřek, is one of several newer Python options. SpaCy, which offers a syntactic dependency parser, named entity recognition, embedded representations, and other functions, is another. So I recruited both Lev Konstantinovskiy — again, Lev serves as gensim community manager — and spaCy creator Matthew Honnibal to speak at the LT-Accelerate conference, taking place November 21-22 in Brussels, to expose an industry-oriented audience to some of the more interesting technical innovations out there.
Call this interview, then —
Topic Modeling for Humans, and the Advance of NLP
Seth Grimes> You’re gensim community manager. What are some of gensim’s strengths?
Lev Konstantinovskiy> Gensim’s slogan is “topic modeling for humans.” The software is a collection of unsupervised algorithms for text. Because they are unsupervised there is no need to spend a lot of time labelling the data. One can just point the algorithm to the corporate datastore and say go. It’s built around the concepts of scalability and data streaming, which is a big deal to some people too.
Gensim is widely used by various companies in production; see our adopters list. The reason for this is that we convert academic papers into industry-level maintainable code, and it turns out people really appreciate it, both in the industry and in academia. Gensim has over 350 academic citations!
We have an active github community that gathers together during the coding sprints at Python and data science conferences.
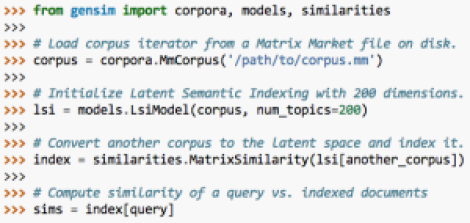 Seth> What’s on the gensim roadmap or already under development?
Seth> What’s on the gensim roadmap or already under development?
Lev> We have big plans on where to take gensim this year in terms of growth, speed and new models. Collaborations and integrations with spaCy, scikit-learn and other ecosystems to make the package easier to use and grow. We are evaluating ways to use GPU and clusters to improve performance. We also have some neural network models in the pipeline in order to achieve state-of-the-art accuracy.
Seth> The definition, “a topic is a probability distribution over the vocabulary,” is quite elegant. (I was reading your KDnuggets article, America’s Next Topic Model. Readers: I recommend it as a technical complement to this interview.) What I’m wondering about, however, is your thoughts about the utility of a 2,500-year-old topic-modeling technique, taxonomy, which is typically used for human-engineered, rather than machine-generated, topic modeling.
Lev> First of all it’s not my definition, it belongs to David Blei and his co-authors on the original LDA [(latent Dirichlet allocation)] paper.
Secondly the taxonomies like wordnet and more modern DBPedia are very useful, for example in synonyms and entity disambiguation.
Seth> You also consult, via RaRe Technologies, founded by Radim Řehůřek, who created gensim. I’m curious about the life of an NLP consultant. What sort of projects do you and colleagues take on?
Lev> We specialize in projects that need to analyze unstructured data, especially text. That’s usually some categorization, recommendations, uncovering hidden themes and topics in a large document collections… not so much the typical run-of-the-mill BI analytics.
Geographically, the clients are mostly in North America, but industry-wise, it’s all over the place… Lots of things happening in HR automation now (analyzing CVs, matching jobs), the media industry, digital security industry to analyze content risk, routing of enterprise support requests, search engines for semantic similarity and executive analytics, legal e-discovery with its specific requirements on statistical robustness…
We get approached almost exclusively for highly innovative projects, stuff nobody’s built before, so it’s usually half-research and half-engineering. And that’s our sweet spot, that’s what we like to do.
Seth> Do clients approach RaRe with a blank slate to address well-defined problems, or do engagements typically start with a discovery phase, to pin down potentially useful unknowns before a data and analysis strategy is devised?
Lev> Discovery is a major part of the process. In our experience, for highly innovative products, it’s not even possible to scope and price a proposal without a proper discovery phase first. We need to analyze the actual business needs, available data, required annotation and SME effort…
The longer we work in the consulting industry, the more importance we give to this phase, because that’s where the true value for the client is. Anyone can mash together a few open source tools, but does it solve what’s really needed?
To be fair, it’s also entirely possible that the data mining field has matured enough that you don’t need to reach out to world-class experts for projects that are completely standard. So there’s a bit of self-selection there – the trivial projects simply don’t reach us. Or at least not until the company has discovered that building something that actually works is not that trivial. 🙂
Seth> What are growth industries or business functions for NLP? Where do you expect the highest proportion of new uptake in the next few years?
Lev> Unsupervised analytics is where it’s at. The biggest boom right now is in classification, but people are realizing it’s really hard to specify goals and classes up-front, and preparing the training data is costly and annoying. Moreover, the goalposts keep shifting, as business requirements change all the time forcing you to re-design your taxonomies, re-label your data… So the unsupervised approach is a winner here.
Also, there’s a long way to go when it comes to the ease of use and ease of deployment. The whole ML field (NLP included) still has that academic feel, where even if there’s this new amazing algorithm that blows everything else out of the water, it’s a long way before anyone can use it. Part of the success behind ecosystems like Hadoop and Spark is this promise of easy deployment. But in reality, as anyone who’s tried using these systems in production will tell you, it’s still a long way off…
We have had consulting clients and gensim users in recruiting, e-publishing, e-commerce and logistics industries. Unstructured text data is everywhere so it’s hard to pinpoint a specific industry that will demand NLP in the next few years.
Seth> What other NLP and analytical tools do you use most frequently? I imagine you have go-to choices for crawling and scraping, perhaps for parsing and information extraction, for data storage, visualization, and other functions. Any non-open source tools?
Lev> Most of our consulting projects use open source tools. I use spaCy and Pattern for parsing, pyLDAvis is for visualising topics. We also jumped on the deep learning wave and use DL models, with Keras as our tool of choice.

No generic tools beyond open source, as our projects usually need building something unique, so off-the-shelf solutions are not that useful.
Seth> I see that you used to do a lot of Spark work. Still? Any streaming text/NLP? Using MLlib or something else?
Lev> MLlib is still quite a new library though it has a good LDA implementation from Intel. I don’t do much Spark work now, previously used it a lot for not-so-NLP tasks like ETL and basket analysis.
Seth> And finally, what NLP tech or applications are going to be hot a year from now? Any predictions? Your LT-Accelerate conference talk is “Turn Email into Data with Deep Learning, Plus Other Industry Tasks with Gensim Topic Modeling.” If you speak again in 2017, what’ll your topic be?
Lev> Deep learning has shown great results is here to stay. For example recurrent neural networks use the context really well to capture intent and emotion in sentiment analysis tasks. I am optimistic that the software and algorithms will mature and in 2017. Fingers crossed that I will be able to give a talk in 2017 titled “Deploy and Build a NLP Deep Learning Pipeline in 2 Easy Steps.” 🙂
Thank you for the opportunity to give this interview. It is an honor to be speaking among the leading industry practitioners at LT-Accelerate 2016.
Seth> Thanks Lev. I’m looking forward to your talk.
Readers who would like to learn more might view video of Lev’s PyData London 2016 talk, Word Embeddings for Fun and Profit in Gensim…