My first reaction, on encountering a recent article, Why the Timing is Right for Knowledge Management Portals, was a sinking feeling — “been there, done that” — a reaction both to the idea of resurrecting the failed portal concept and to the thought that respectable folks still see knowledge as manageable, in this, the Internet era, when facts, opinions, and expertise move at light speed.
 There’s little exciting in KM as it has long (although serviceably) been defined, as the industry has long conceived it. Industry’s idea is that an enterprise can beneficially manage knowledge by a) storing and organizing documents and providing a search function and b) cataloging employee abilities and facilitating collaboration. This approach works for some, but in my view, it delivers half-truths. It ignores the information inside documents. It ignores enterprise-relevant knowledge and expertise that resides outside an organization’s boundaries, out in the wild-and-wooly online and social universe. It largely ignores the social voice of the customer, business partner (and competitor) information, the wisdom of communities of practice and industry authorities, and the like.
There’s little exciting in KM as it has long (although serviceably) been defined, as the industry has long conceived it. Industry’s idea is that an enterprise can beneficially manage knowledge by a) storing and organizing documents and providing a search function and b) cataloging employee abilities and facilitating collaboration. This approach works for some, but in my view, it delivers half-truths. It ignores the information inside documents. It ignores enterprise-relevant knowledge and expertise that resides outside an organization’s boundaries, out in the wild-and-wooly online and social universe. It largely ignores the social voice of the customer, business partner (and competitor) information, the wisdom of communities of practice and industry authorities, and the like.
KM’s short-comings aren’t going to be overcome solely, or primarily, by better data hygiene or consistent approaches to applying metadata, or by putting a new face — a reworked portal — on the same old searchable document sets. What’s needed?
A NewKM Need
My view: It’s time to bring knowledge to knowledge management, via:
- Analytics, specifically, exhaustive information extraction (and not just searchable documents) and then data mining to identify links and associations;
- An end to artificial boundaries, to neglect of extra-mural information;
- Purpose-driven, ad-hoc communities and collaboration (and not just rosters of experts); and
- Actual facts and connections, as captured in social and knowledge graphs.
(Information extraction is the resolution of entities, pattern-based information such as events, topics, concepts, sentiment, and relationships of interest within source media, whether text, images, audio, or video. IE may involve structural, statistical, and machine learning (ML) methods, that is machine intelligence or AI. Whatever the method applied, the aim is to discover relevant data wherever it occurs.
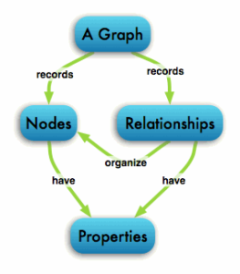
(The graphs I’m referring to are network and property graphs, data structures that capture entities of interest — whether people, places, and organizations or products, components, and parts or something else — and their attributes and interconnections, as nodes, annotations, and edges.)
Seth Earley, whose “Why the Timing…” portal article I cited, is deservedly a recognized information-management authority. His views and mine do align to an extent, judging from a concluding line in his article. Seth observes that “organizations are weighed down with legacy technologies” and that access difficulty stems primarily from “the underlying structures of corporate content and data.” He expects that “knowledge management portals will continue to evolve with machine learning, natural language processing (NLP), and social collaboration integration.” Replace “management portals” in that sentence and you’re golden. It’s knowledge we should focus on! Rewriting: Knowledge discovery will continue to evolve with machine learning (ML), natural language processing (NLP), and social collaboration integration.
As for portals as an access mechanism, they will remain a choke-point, given all the enterprise-relevant information they can’t get at. And while the tired document-centered data structures that sit behind KM portals will become more flexible via ML, NLP, and collaboration, what you get out of them will continue to be records rather than knowledge.

Some Get It, Somewhat, and Some Don’t
Judging from the agenda of last November’s KMWorld conference (where I spent a day), unlike Seth Earley, the broad KM community largely doesn’t get analytics, openness, network, or knowledge bases. The KM community seems largely inward focused, ignorant of the applicability to KM of the machine intelligence innovations discussed above, which not incidentally have long-since be proven by Google, Facebook, IBM, and a host of providers in the semantic space, as well as by businesses applying them in customer experience, consumer insights, social/media analysis, life sciences, and a spectrum of other initiatives. But fortunately there are KM exceptions. For one —
Safeharbor Knowledge Solutions, which I learned about via a Brainspace blog article, differentiates document management and (true) knowledge management, explaining,
A knowledge base is not just a document repository – it’s a body of knowledge that is continuously evolving. Knowledge consists of answers shared by experts, information hidden away in emails, ideas and feedback found in article comments and community forum discussions. A knowledge base application is designed to capture knowledge as it’s created and make it easy to find.
So that’s my ingredient #4, above.
While Brainspace isn’t positioned as a KM provider — text analytics forms the core of their product line — the blog article I mentioned relates to KM: The Key to Knowledge Management and Innovation is Knowledge Flow, Part 1. Brainspace’s Flow concept extends to external market intelligence and enterprise social networks so let’s award Brainspace half a point on ingredient #2.
Brainspace gets more points for pointing us to another article, Build Better Knowledge Management, by Christian Buckley, a long-time KM industry participant. Buckley writes,
The problem with knowledge management (KM) is… a user experience that fails to align the needs of the complex, non-linear playback mechanisms of the human brain with our systems of record…
To build the next generation KM platform, we need solutions that can:
- Improve the distribution of knowledge and ideas, quickly and seamlessly
- Automatically identify patterns and themes within that content
- Expand upon, refine and convert that knowledge based on those patterns, and in context to our requirements, ultimately making it searchable (i.e. findable)
- Correlate those patterns and themes, and take appropriate action — with those actions also tracked and measured, as an extension of the ideas
Brainspace’s Brandon Gadoci writes, however, that “Buckley is speaking wishfully. Most companies have no such platform.” True, and that’s a challenge and an opportunity, to bring knowledge — patterns and themes, refined, findable, supporting action — to knowledge management. What portal is going to, per Christian Buckley, “improve the distribution of knowledge and ideas, quickly and seamlessly”?
But all the same, none of this KM-insider evangelism breaks out of the enterprise-as-knowledge-island KM self-limitation. For that, we should seek truly new elements in…
A NewKM Agenda
The agenda that will advance KM involves analytics and information extraction — bridging boundaries, crossing into the online and social world — and an admission that records and documents are merely contains and that searchability does not constitute knowledge. The tech to support this agenda is out there, freely available and quite capable, flexible, and performant. So a NewKM agenda would have to start with the realization that a closed mindset — records as closed books and needless barriers — hinders knowledge management. Extract knowledge from documents. Structure it for query and analysis and not just retrieval. Work, collaboratively, across corporate boundaries. And find the knowledge in knowledge management.
The ultimate underlying issue is the failure to provide a comprehensive integrated means for dealing with the semantics of data in computing – for most data it is the information contained in it, not its form that is the issue. First the logicians, such as Carnap prior to the age of computing, tried to address that issue, Then the researchers in AI/knowledge representation, (e.g., John Sowa’s conceptual structures project at IBM, and the `Semantic Web’)). But nothing has worked because they failed to resolve the basic issue, viz., developing an adequate mathematical model of information, i.e., of the conceptual semantics of language.
My background is in mathematics and, by ignoring everything else that has been done, including predicate calculus, and employing a math modelling approach, I have developed a rigorous mathematical model of information that accounts for all of the conceptual semantics of language (as identified by the semanticists), based on three very simple primitive constructs. In addition I have defined a very simple formal language that maps more or less isomorphically to that semantic model and can be used to express any and all information via very simple structures that avoid the structural problems of predicate calculus for storage and processing in computer systems. Also, because the language corresponds as closely as possible to the form in which information is stored in human memory, it is very compatible with human thought and communication. The system has been reviewed by a logician who has stated in writing that it is `light years’ ahead of anything else he has seen.
I believe that, in addition to providing a comprehensive universal form for the storage of information in computer systems and for the subject-indexing of all forms of data, the language system can also be used in various ways to greatly enhance NLP, as well as the translation between all different data forms, including NL, by providing a universal intermediate translational form, as well as a contextual-information base that can be employed in resolving semantic ambiuities
My objective is to set up an institute to support the implementation of the system in IT and then sell that institute to the licensee companies. The reason I am contacting you at this point is twofold: first, to let you know in advance re the pending availability of the system, i.e., after the patent application is filed in a few months; second, due to the depletion of funds I have started a crowdfunding campaign to finance the the patent application, etc., and could use your advice re publicizing that effort.